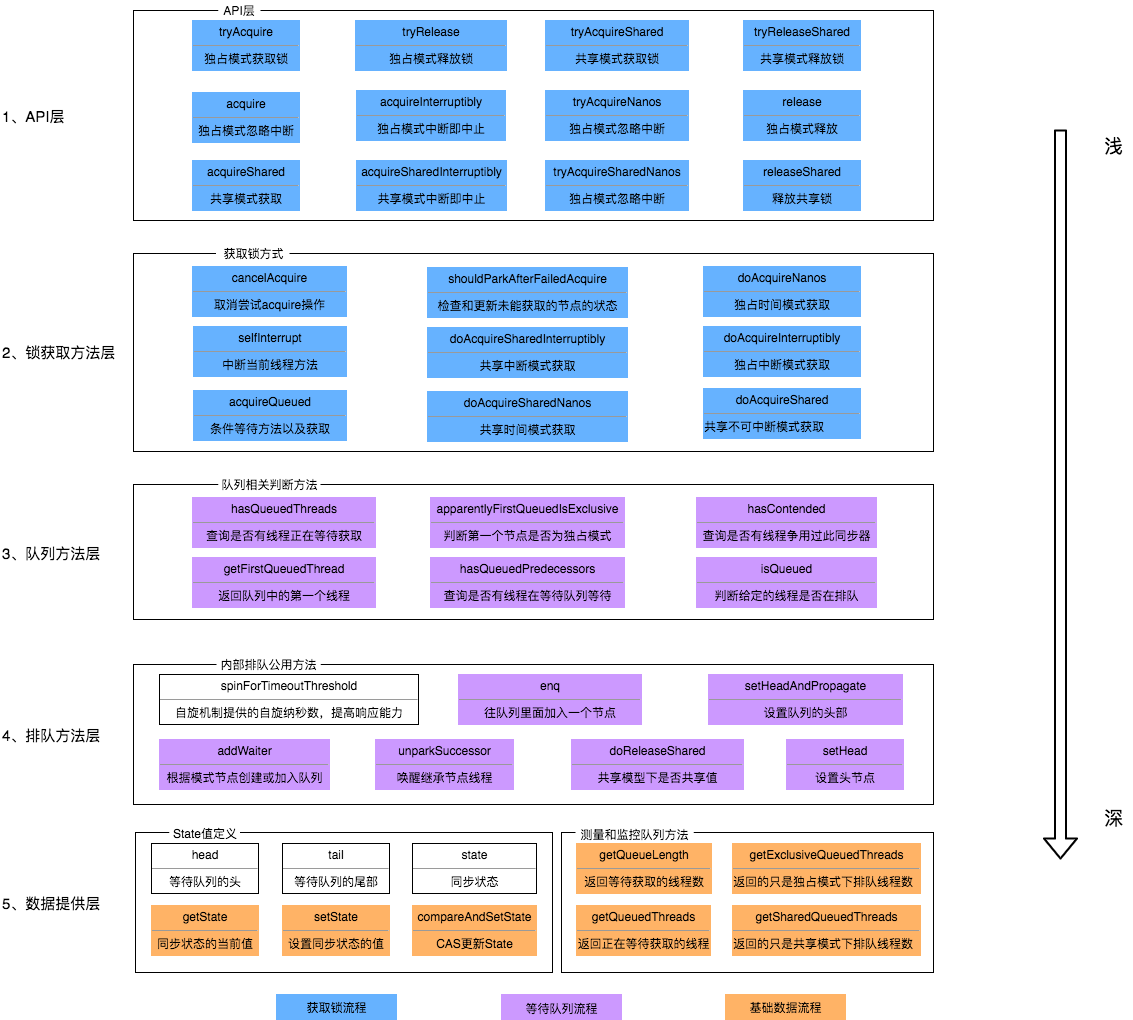
RocketMQ
持久化 & 多副本
RocketMQ默认配置为 3副本、异步复制、异步刷盘,类比kafka的的replica_factor=3, acks=leader;在这种配置之下,可靠性99.99%,可用性99.95%
同时可以针对特殊场景,提供同步刷盘、同步复制的集群,提供更高的可靠性,在6副本、同步复制、同步刷盘的配置下,消息可靠性可达9个9。相应的,写入延时会升高,qps、availability会降低
RocketMQ的消息默认保留48小时,由于存储模型的关系,这个配置是集群级别的,不像kafka是topic级别的。所以如果有特殊的需求,请联系@沈辉 视情况单独搭建集群
消息重试(Requeue)
kafka设计之初主要作为 log (特指类似binlog这种WAL)的传输总线,同一个partition内的有序是默认需求,这意味着消费失败的消息是不能重入的,否则消息的顺序性就被破坏了;用户需要自己打日志或者转储来处理消费失败的消息。
而在MQ领域,大多数场景下其实并不需要严格的顺序,对于消费失败的消息(可能是消费者下游短时间不可用、load高等),这种情况下用户希望消息能够重新投递到MQ,可以不用额外写代码处理错误的消息。RocketMQ 在非有序消费模式下,支持消息重试,类比NSQ的requeue机制,并且重试的消息具有和普通消息一样的持久化支持。
死信队列 (Dead Letter Queue)
当消息多次重试仍然消费失败,这种情况多半是消费者逻辑有问题,比如对于消息的某些字段没有兼容等;需要有地方能够转储这一批消息。RocketMQ提供了死信队列,消费者可以指定消息最大重试次数,当消息重试超过该次数,消息将会发往死信队列。待消费者的问题解决之后,可以从死信队列拉取这些消息统一处理。
延时消息
一些场景下,生产者发送消息成功后,希望delay一段时间消息再投递给消费者,比如创建一个订单之后30分钟内未支付则取消订单的场景。
NSQ支持ms级别精度的延时消息,其实现为内存里的一个priority queue,没有持久化;kafka不支持延时消息;当前版本的RocketMQ支持分级的时延,比如支持10s、30s、1min、5min、10min、15min、20min、30min等多个级别时延,足够覆盖大部分场景,并且有持久化。
需要任意时延的延迟消息用户,见: 延时消息用户文档
写入延迟保障
RocketMQ和kafka都是顺序写盘,充分利用page cache以获得低时延和吞吐。kafka的存储模型为每个partition都由若干segment(物理文件)组成的逻辑文件,当kafka集群上的topic/partition数量多了之后,kafka的顺序写可能会逐渐退化到随机写,写入延迟上涨;只能拆分集群,减少单集群上topic/partition数量。
而RocketMQ的存储模型与kafka不同,所有消息都写到一个CommitLog中即返回,再异步将offset、length信息dispatch到各Consume Queue中,所以是严格的顺序写,在topic数量很多的时候,page fault仍然维持在低水平,写入时延较为稳定。
在异步复制、异步刷盘下,写入延时的avg为10ms,pct99为20ms
基于时间回溯
比如30分钟前消费者下游故障,期间消费者全部异常,用户希望将消费进度回拨到30min前,达到”补”消息的效果。kafka需要集群版本在0.10以上才能支持,RocketMQ默认支持。
顺序/乱序消费
RocketMQ同时提供了顺序和乱序消费。 顺序的保障是,消息写到broker上的一个Consume Queue的顺序和消费者从该Consume Queue读取的顺序是一致的,多个producer并发写到一个Consume Queue的状况顺序没有保障,实际的顺序以broker收到的顺序为准。
一般有序消息都是同步发送的,也即msg n发送成功并且client收到写入成功的结果之后才会发送msg n+1,异步/并发的有序消息是个伪需求。
对于消息没有顺序要求的场景,可以使用乱序消费,并发度为消费者实例数 * 线程/协程数。
长轮询
长轮询通过客户端和服务端的配合,达到主动权在客户端,同时也能保证数据的实时性;长轮询本质上也是轮询,只不过对普通的轮询做了优化处理,服务端在没有数据的时候并不是马上返回数据,会hold住请求,等待服务端有数据,或者一直没有数据超时处理,然后一直循环下去;下面看一下如何简单实现一个长轮询;
暂不提供什么
- 广播消费(TBD)
即同一个consumer group内的所有消费者每一个实例都能收到全量消息;可以通过每个消费者使用独立的Consumer group达到效果。 - 事务消息 (TBD)
事务消息指:Producer发消息和Producer的其他操作(如写DB)形成事务,如果其他操作Commit,则消息Consumer可见;如果其他操作Rollback,则消息也不会投递给Consumer。
原生的RocketMQ的java SDK支持事务消息,现阶段其他语言暂不支持,后续会支持。
vs Kafka
(1) 适用场景
Kafka适合日志处理;
RocketMQ适合业务处理。
(2) 性能
Kafka单机写入 TPS 号称在百万条/秒;
RocketMQ 大约在10万条/秒。
结论:追求性能的话,Kafka单机性能更高。
(3) 可靠性
RocketMQ支持异步/同步刷盘;异步/同步Replication;
Kafka使用异步刷盘方式,异步Replication。
结论:RocketMQ所支持的同步方式提升了数据的可靠性。
(4) 实时性
均支持pull长轮询,RocketMQ消息实时性更好
结论:RocketMQ 胜出。
(5) 支持的队列数
Kafka单机超过64个队列/分区,消息发送性能降低严重;
RocketMQ 单机支持最高5万个队列,性能稳定
结论:长远来看,RocketMQ 胜出,这也是适合业务处理的原因之一
(6) 消息顺序性
Kafka 某些配置下,支持消息顺序,但是一台Broker宕机后,就会产生消息乱序;
RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,
发送消息会失败,但是不会乱序;
结论:RocketMQ 胜出
(7)消费失败重试机制
Kafka消费失败不支持重试
RocketMQ消费失败支持定时重试,每次重试间隔时间顺延。
(8)定时/延时消息
Kafka不支持定时消息;
RocketMQ支持定时消息
(9)分布式事务消息
Kafka不支持分布式事务消息;
阿里云ONS支持分布式定时消息,未来开源版本的RocketMQ也有计划支持分布式事务消息
(10)消息查询机制
Kafka不支持消息查询
RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息
(11)消息回溯
Kafka理论上可以按照Offset来回溯消息
RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息