特点
真正的列式数据库管理系统
完备的DBMS功能
数据压缩
数据的磁盘存储
多核心并行处理
多服务器分布式处理
支持SQL基于SQL的声明式查询语言 ,它在许多情况下与ANSI SQL标准 相同。
向量引擎
实时的数据更新
索引
支持近似计算
用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
Adaptive Join Algorithm
支持数据复制和数据完整性
表引擎
适用于高负载,最强大的表引擎
同构后续的后台数据处理,快速插入数据,然后应用规则在后台合并这些部分
支持数据复制、分区、辅助数据跳过索引以及其他引擎不支持的其他功能
Log
轻量级引擎,功能最少。当您需要快速编写许多小表(最多约100万行)并在以后作为一个整体读取它们时,它们是最有效的。
Integration Engines
Special Engines(特殊引擎,不知道如何分类,ClickHouse特有的)
高阶函数
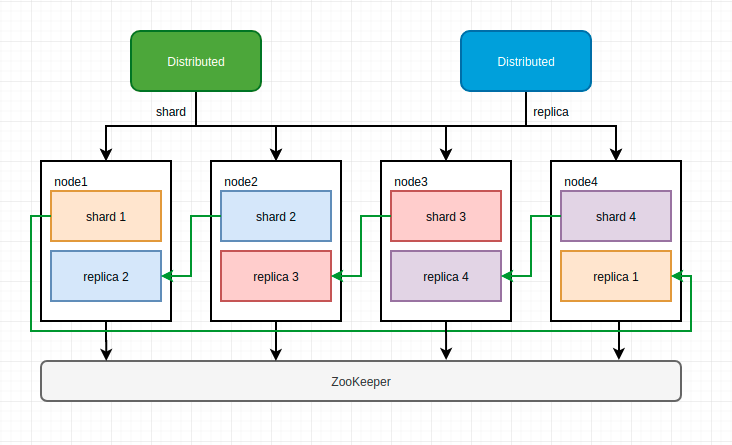
集群架构 ClickHouse 不同于 Elasticsearch、HDFS 这类主从架构的分布式系统,它采用多主(无中心)架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。
ClickHouse 借助分片将数据进行横向切分,而分片依赖集群,每个集群由 1 到多个分片组成,每个分片对应了 CH 的 1 个服务节点;分片数量的上限取决与节点数量(1 个分片只能对应 1 个服务节点 )。
但是 ClickHouse 并不像其他分布式系统那样,拥有高度自动化的分片功能;CH 提供了本地表与分布式表的概念;一张本地表等同于一个数据分片。而分布式表是张逻辑表,本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。当然,也可以在应用层实现数据分发。
ClickHouse 同时支持数据副本,其副本概念与 Elasticsearch 类似,但在 CH 中分片其实是一种逻辑概念,其物理承载是由副本承担的。
ClickHouse 的数据副本一般通过 ReplicatedMergeTree 复制表系列引擎实现,副本之间借助 ZooKeeper 实现数据的一致性。此外也可通过分布式表负责同时进行分片和副本的数据写入工作。
存储组织结构
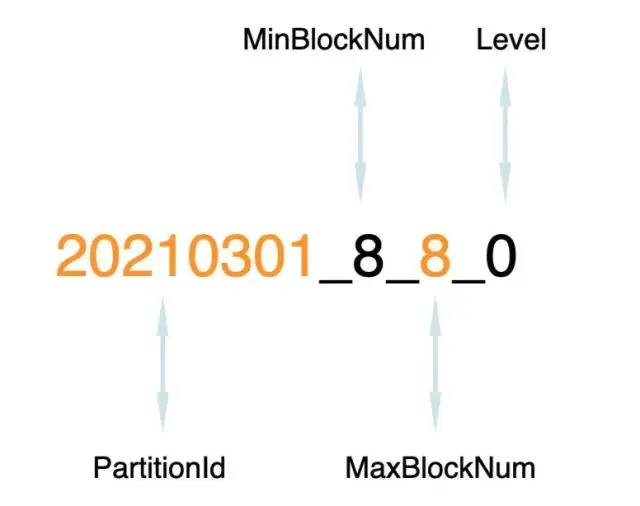
分区目录 分区目录命名 多个分区目录组成一个分区,目录命名规则如下:
PartitionId_MinBlockNum_MaxBlockNum_Level
PartitionID:分区id,例如20210301。
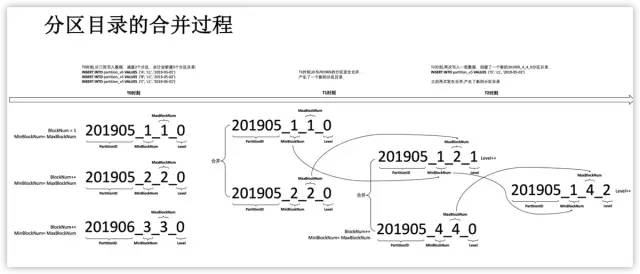
分区目录合并
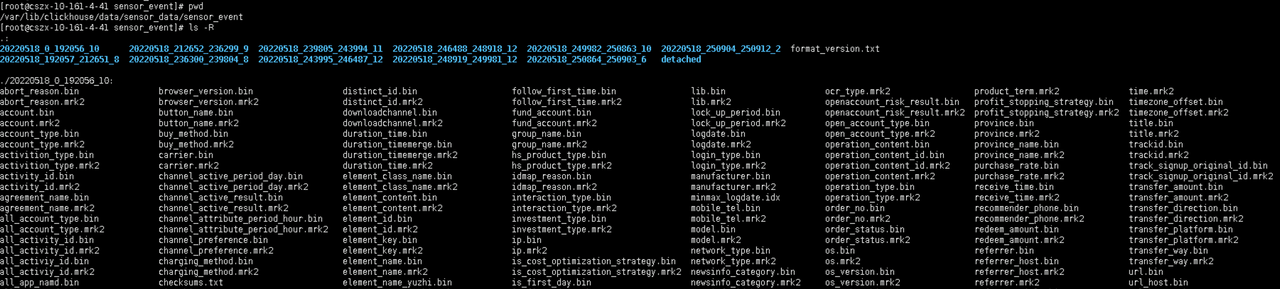
数据 目录内文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 *── 200002 _1_1_0 * *── Birthday.bin * *── Birthday.mrk2 * *── checksums.txt * *── columns .txt * *── count.txt * *── Id.bin * *── Id.mrk2 * *── minmax_Birthday.idx * *── Name.bin * *── Name.mrk2 * *── partition.dat * *── primary.idx *── detached *── format_version.txt
文件名
描述
作用
primary.idx
索引文件
用于存放稀疏索引
[Column].mrk2
标记文件
保存了bin文件中数据的偏移信息,用于建立primary.idx和[Column].bin文件之间的映射
[Column].bin
数据文件
存储数据,默认使用lz4压缩存储
partition.dat
分区文件
用于保存分区表达式生成的值
minmax_[Column].idx
minmax索引
用于记录当前分区下分区字段的最小最大值
columns.txt
列信息文件
用于保存表的列字段信息
count.txt
计数文件
用于记录当前分区目录下数据的总行数
checksums.txt
校验文件
存放以上各个文件的size以及哈希值,用于快速校验文件的完整性
primary.idx结构 0cd44d48-2323-4aa9-9020-b22c51f58395.png
.mrk2 54e7d7ec-10af-4e22-9f93-dac77d4b9342.png
Offset in compressed file,8 Bytes,代表该标记指向的压缩数据块在bin文件中的偏移量。
Offset in decompressed block,8 Bytes,代表该标记指向的数据在解压数据块中的偏移量。
Rows count,8 Bytes,行数,通常情况下其等于index_granularity。86c3005c-373c-4ca9-91ee-9f030707baf3.png
.bin 409a3098-cfe5-4da7-b410-7912e7532d91.png
Checksum ,16 Bytes,用于对后面的数据进行校验。Compression algorithm ,1 Byte,默认是LZ4,编号为0x82。Compressed size ,4 Bytes,其值等于Compression algorithm + Compressed size + Decompressed size + Compressed data的长度Decompressed size ,4 Bytes,数据解压缩后的长度。Compressed data ,压缩数据,长度为Compressed size - 9。
索引过程 12b5387a-cb0a-4955-882a-8c8fcb846f18.png 691d5682-433f-42f3-aac8-cb70d4c78a1e.png
二级索引(跳树索引) 一级索引决定了数据排布的方式,但是当满足最左前缀原则时,数据查询需要扫描全部文件,这时候可以借助二级索引进行加速。
minmax
set(max_rows)
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
MergeTree 建表语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CREATE TABLE [IF NOT EXISTS ] [db.]table_name [ON CLUSTER cluster]( name1 [type1] [DEFAULT | MATERIALIZED| ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT | MATERIALIZED| ALIAS expr2] [TTL expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2, ... PROJECTION projection_name_1 (SELECT < COLUMN LIST EXPR> [GROUP BY ] [ORDER BY ]), PROJECTION projection_name_2 (SELECT < COLUMN LIST EXPR> [GROUP BY ] [ORDER BY ]) ) ENGINE = MergeTree() ORDER BY expr,column1,cloumn2[PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE | TO DISK 'xxx' | TO VOLUME 'xxx' [, ...] ] [WHERE conditions] [GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ] [SETTINGS name= value , ...]
[必填选项]
[选填选项]
ReplacingMergeTree 该引擎适合于经常要根据’主键’进行数据更新的数据(upsert),主键加引号是因为,其实是根据order by定义的字段而不是根据primary key的字段去重的.
SummingMergeTree,AggregatingMergeTree 预聚合表引擎,此引擎适合于要查询聚合结果而不关心明细数据的场景,比如查询的是每个人月的销量综合,而不是每一单的实际销量.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 CREATE TABLE mydatabase.amTest( `id` Int8, `name` String, `code` AggregateFunction(uniq, String), `date ` Date , `score` AggregateFunction(sum, Int16), `score2` AggregateFunction(avg, Int16) ) ENGINE = AggregatingMergeTree PARTITION BY date ORDER BY (id, name);CREATE MATERIALIZED VIEW amTestENGINE = AggregatingMergeTree PARTITION BY date primary key(id,name)ORDER BY (id, name,sex)AS SELECT id,name,date ,uniqState(code),sumState(score) as score,avgState(score) as score2 FROM xxx GROUP BY id,name;
CollapsingMergeTree,VersionedCollapsingMergeTree 这种引擎的适应场景在于有些时候需要删除数据或者更新数据。很少使用。
分布式 ClickHouse学习系列之四【副本&分片部署说明】
集群配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <remote_servers> <ck_cluster> <shard> <weight>1</weight> <internal_replication>true</internal_replication> <replica> <host>10.161.4.40</host> <port>9000</port> <user>default</user> <password>clickhouse9z</password> </replica> </shard> <shard> <weight>1</weight> <internal_replication>true</internal_replication> <replica> <host>10.161.4.41</host> <port>9000</port> <user>default</user> <password>clickhouse9z</password> </replica> </shard> <shard> <weight>1</weight> <internal_replication>true</internal_replication> <replica> <host>10.161.4.42</host> <port>9000</port> <user>default</user> <password>clickhouse9z</password> </replica> </shard> </ck_cluster> </remote_servers>
ReplicatedMergeTree 1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE IF NOT EXISTS data.event_local ON CLUSTER ck_cluster( `event` String, `user_id` Int64, `distinct_id` String, `date ` Date , `time ` DateTime, `timezone_offset` Float64, `logdate` Date ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/event' ,'{replica}' ) PARTITION BY logdateORDER BY (event,user_id,receive_time)sample by intHash32(user_id);
我们在创建表的时候指定了ReplicatedMergeTree(xxxx),里面传递了两个参数,我们对这两个参数一一描述
/clickhouse/tables/ 这一部分指定的是在ZK上创建的路径地址,可随意变换只要记得即可{shard} 指的是分片的标志,同一个分片内的所有机器应该保持相同。建议使用使用的是集群名+分片名的配置也就是{layer}-{shard}{replica} 参数建议在macros配置成机器的hostname,因为每台机器的hostname都是不一样的,因此就能确保每个表的识别符都是唯一的了
当使用ON CLUSTER创建表时,{shard}和{replica}clickhouse会自动填充,而且在集群内任意一台机器执行即可,不需要在所有机器执行
Distributed 分布式引擎本身不存储数据 , 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
例:event_local
1 2 3 CREATE TABLE IF NOT EXISTS data.event ON CLUSTER ck_clusterAS data.event_localENGINE = Distributed(ck_cluster, data, event_local,int64hash(user_id));
GLOBAL & LOCAL 使用distributed表时,查询会下推到各个分片执行,多个结果再UNION到一起。如果在查询中使用子查询,通常要使用GLOBAL参数(GLOBAL IN/GLOBAL JOIN)来保证子查询数据的汇总。ClickHouse分布式IN & JOIN 查询的避坑指南
#高阶函数ClickHouse 高阶函数
数据导入 Datax
{
"job":
{
"setting":
{
"speed":
{
"channel":10
},
"errorLimit":
{
"record": 0,
"percentage": 0.02
}
},
"content":
[
{
"reader":
{
"name": "hdfsreader",
"parameter":
{
"path": "/user/hive/warehouse/data.db/event/logdate=20220518",
"defaultFS": "hdfs://x.x.x.x:xxxx",
"column":
[
{"index": 0, "type": "string"}, {"index": 1, "type": "long"}, {"index": 2, "type": "string"}, {"index": 3, "type": "date"}, {"index": 4, "type": "date"} {"value": "20220518", "type": "string"}
],
"fileType": "orc",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer":
{
"name": "clickhousewriter",
"parameter":
{
"username": "default",
"password": "clickhouse9z",
"column":
[
"event",
"user_id",
"distinct_id",
"date",
"logdate"
],
"connection":
[
{
"jdbcUrl": "jdbc:clickhouse://x.x.x.x:xxxx/data",
"table":
[
"event"
]
}
]
}
}
}
]
}
}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}