统计语言模型
NNLM 模型
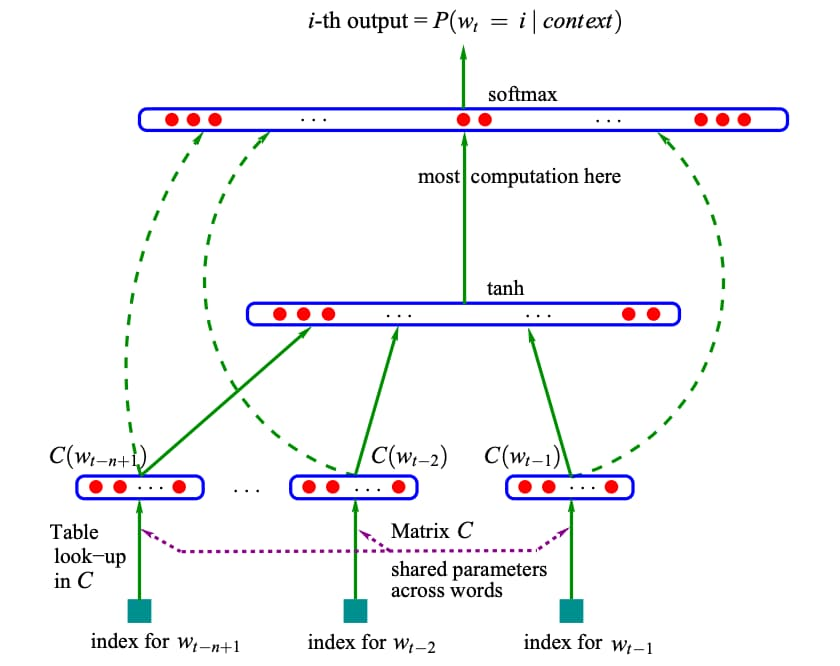
NNLM 模型首先从词表C中查询得到前面N-1个词语对应的词向量,然后将这些词向量拼接后输入到带有激活函数的隐藏层中,通过Softmax函数预测当前词语的概率。特别地,包含所有词向量的词表矩阵C也是模型的参数,需要通过学习获得。因此 NNLM 模型不仅能够能够根据上文预测当前词语,同时还能够给出所有词语的词向量(Word Embedding)。
word2vec
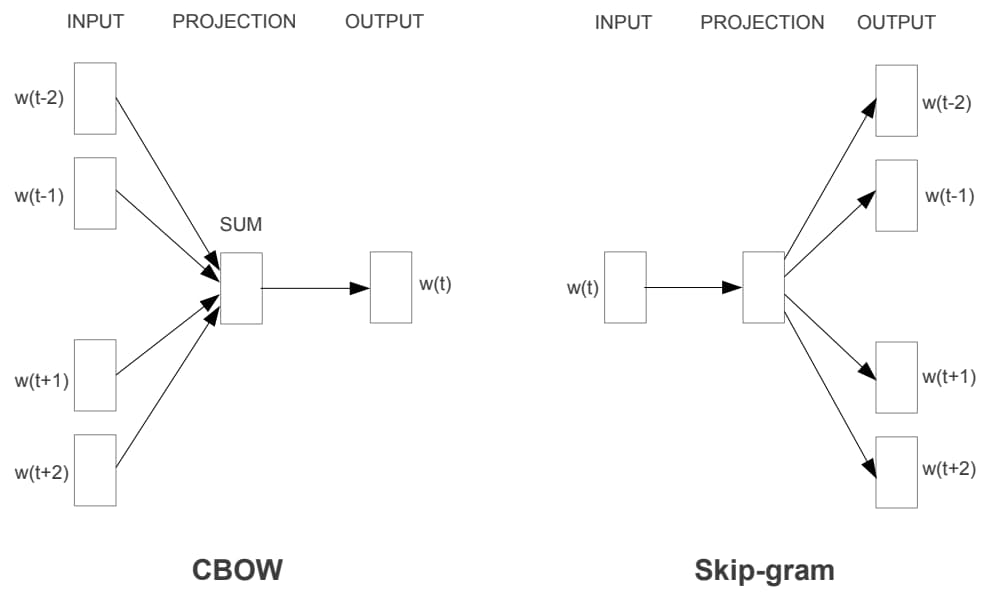
CBOW (Continuous Bag-of-Words)使用周围的词语w(t-2),w(t-1),w(t+1),w(t+2)来预测当前词w(t)。而 Skip-gram 则正好相反,它使用当前词w(t)来预测它的周围词语。
与严格按照统计语言模型结构设计的 NNLM 模型不同,Word2Vec 模型在结构上更加自由,训练目标也更多地是为获得词向量服务。特别是同时通过上文和下文来预测当前词语的 CBOW 训练方法打破了语言模型“只通过上文来预测当前词”的固定思维,为后续一系列神经网络语言模型的发展奠定了基础。
word2vec最大的问题是无法解决一词多义问题。后来自然语言处理的标准流程就是先将 Word2Vec 模型提供的词向量作为模型的输入,然后通过 LSTM、CNN 等模型结合上下文对句子中的词语重新进行编码,以获得包含上下文信息的词语表示。
ELMo 模型
ELMo 模型(Embeddings from Language Models)更好地解决多义词问题。与 Word2Vec 模型只能提供静态词向量不同,ELMo 模型会根据上下文动态地调整词语的词向量。
ELMo 模型首先对语言模型进行预训练,使得模型掌握编码文本的能力;然后在实际使用时,对于输入文本中的每一个词语,都提取模型各层中对应的词向量拼接起来作为新的词向量。ELMo 模型采用双层双向 LSTM 作为编码器,如图 1-10 所示,从两个方向编码词语的上下文信息,相当于将编码层直接封装到了语言模型中。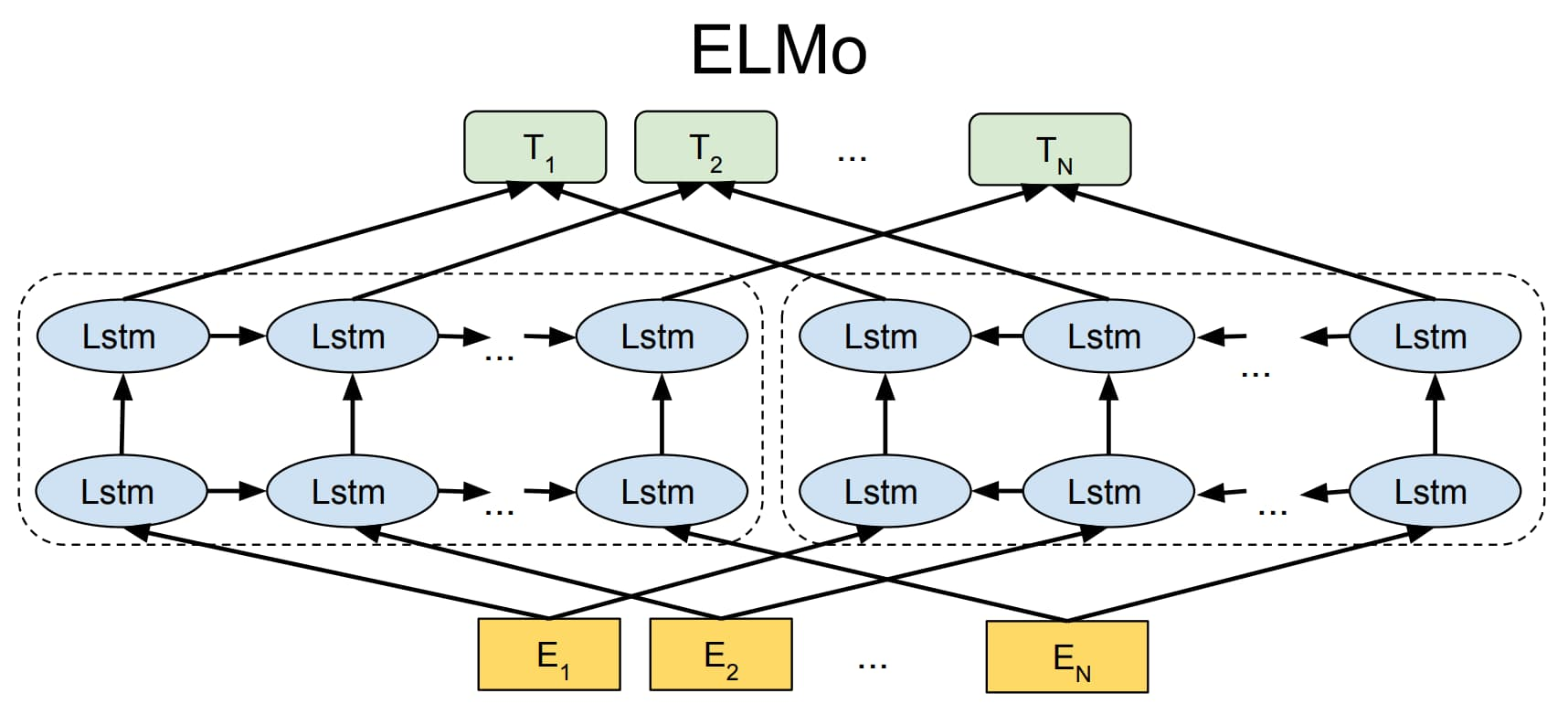
训练完成后 ELMo 模型不仅学习到了词向量,还训练好了一个双层双向的 LSTM 编码器。对于输入文本中的词语,可以从第一层 LSTM 中得到包含句法信息的词向量,从第二层 LSTM 中得到包含语义信息的词向量,最终通过加权求和得到每一个词语最终的词向量。
BERT模型
BERT 模型采用和 GPT 模型类似的两阶段框架,首先对语言模型进行预训练,然后通过微调来完成下游任务。但是,BERT 不仅像 GPT 模型一样采用 Transformer 作为编码器,而且采用了类似 ELMo 模型的双向语言模型结构。由于 BERT 模型采用双向语言模型结构,因而无法直接用于生成文本。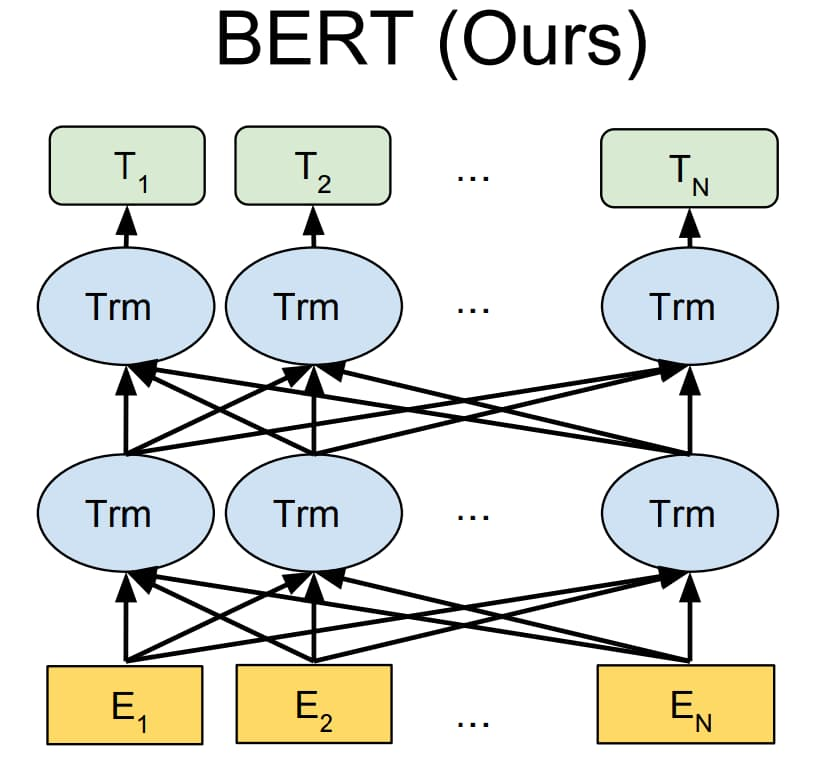
Transformer模型
Transformer模型按模型结构将它们大致分为三类:
- 纯 Encoder 模型(例如 BERT),又称自编码 (auto-encoding) Transformer 模型;
- 纯 Decoder 模型(例如 GPT),又称自回归 (auto-regressive) Transformer 模型;
- Encoder-Decoder 模型(例如 BART、T5),又称 Seq2Seq (sequence-to-sequence) Transformer 模型。
Transformer 模型本质上是预训练语言模型,大都采用自监督学习 (Self-supervised learning) 的方式在大量生语料上进行训练,训练这些 Transformer 模型完全不需要人工标注数据。
例如下面两个常用的预训练任务:
- 基于句子的前n个词来预测下一个词,因为输出依赖于过去和当前的输入,因此该任务被称为因果语言建模 (causal language modeling);
- 基于上下文(周围的词语)来预测句子中被遮盖掉的词语 (masked word),因此该任务被称为遮盖语言建模 (masked language modeling)。
结构
标准的 Transformer 模型主要由两个模块构成:
Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。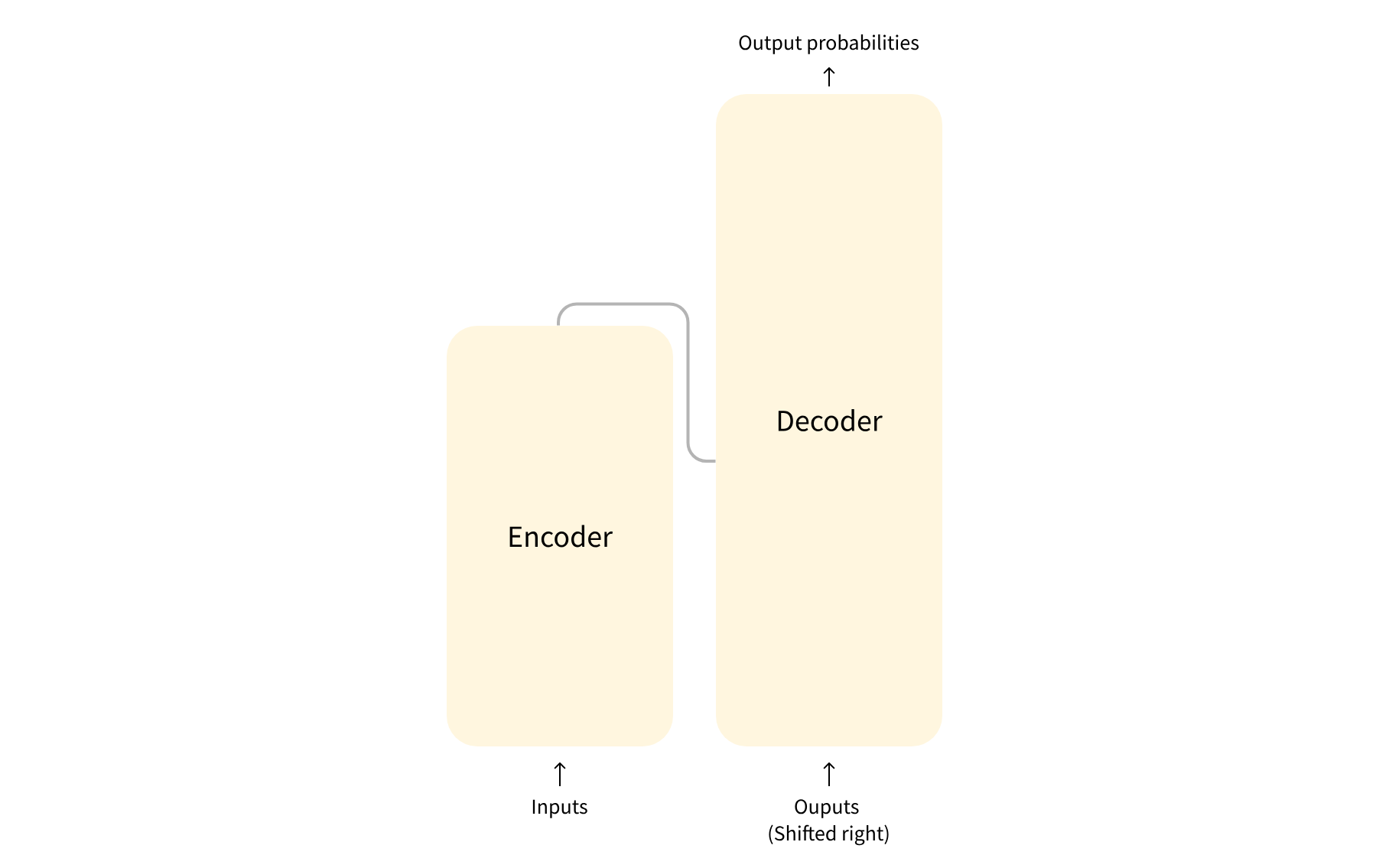
这两个模块可以根据任务的需求而单独使用:
- 纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
- 纯 Decoder 模型:适用于生成式任务,例如文本生成;
- Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译、摘要。
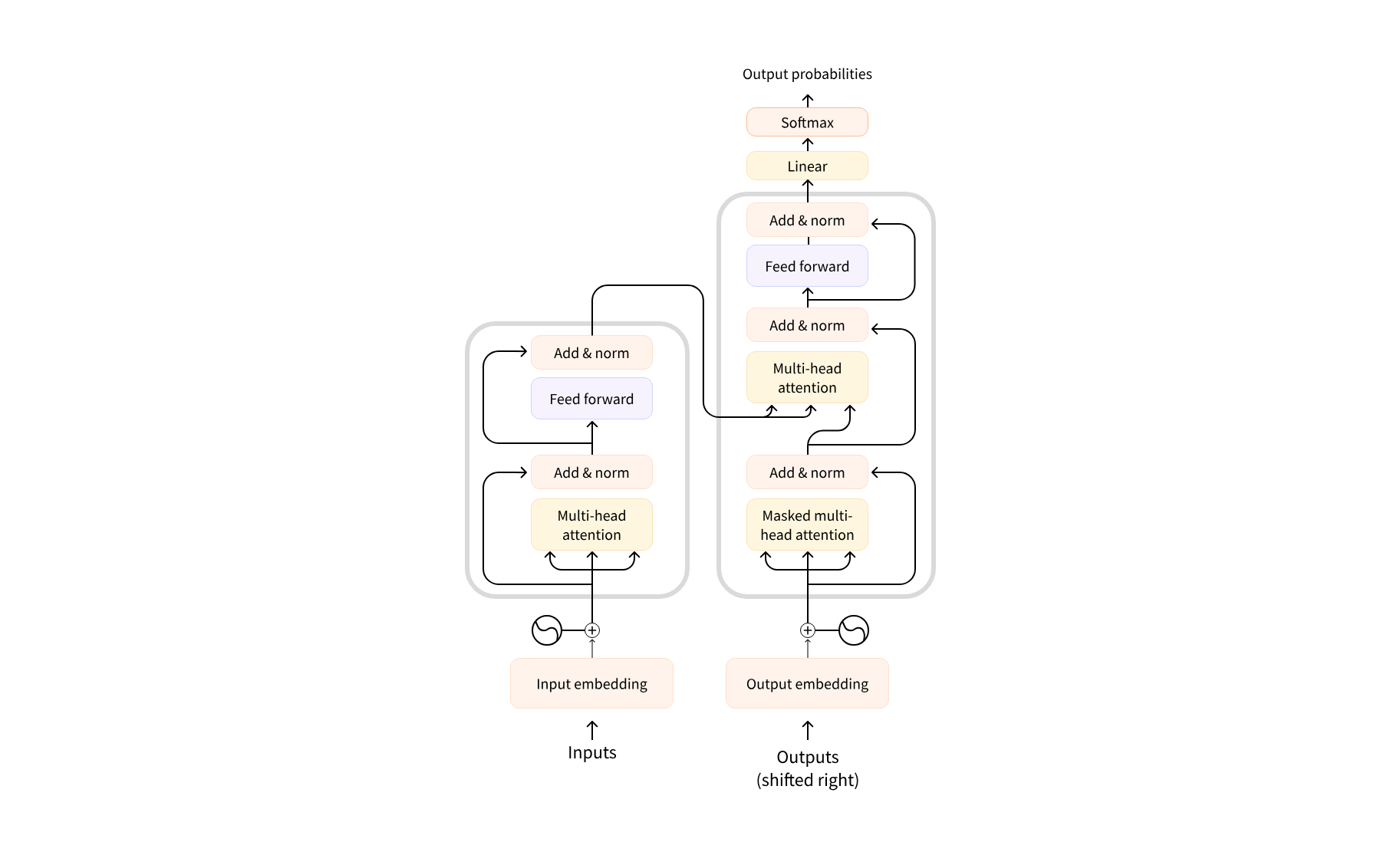
Attention
注意力层的作用就是让模型在处理文本时,将注意力只放在某些词语上。
例如要将英文“You like this course”翻译为法语,由于法语中“like”的变位方式因主语而异,因此需要同时关注相邻的词语“You”。同样地,在翻译“this”时还需要注意“course”,因为“this”的法语翻译会根据相关名词的极性而变化。对于复杂的句子,要正确翻译某个词语,甚至需要关注离这个词很远的词。
同样的概念也适用于其他 NLP 任务:虽然词语本身就有语义,但是其深受上下文的影响,同一个词语出现在不同上下文中可能会有完全不同的语义(例如“我买了一个苹果”和“我买了一个苹果手机”中的“苹果”)。
NLP神经网络模型的本质就是对输入文本进行编码,常规的做法是首先对句子进行分词,然后将每个词语 (token) 都转化为对应的词向量 (token embeddings),这样文本就转换为一个由词语向量组成的矩阵X=(x1,x2,…,xn),其中 xi就表示第i个词语的词向量,维度为d,故 X∈Rn*d。
在 Transformer 模型提出之前,对 token 序列 X 的常规编码方式是通过循环网络 (RNNs) 和卷积网络 (CNNs)。
- RNN(例如 LSTM)的方案很简单,每一个词语 xt 对应的编码结果 yt通过递归地计算得到:yt=f(y(t-1),xt)。
RNN 的序列建模方式虽然与人类阅读类似,但是递归的结构导致其无法并行计算,因此速度较慢。而且 RNN 本质是一个马尔科夫决策过程,难以学习到全局的结构信息; - CNN 则通过滑动窗口基于局部上下文来编码文本,例如核尺寸为 3 的卷积操作就是使用每一个词自身以及前一个和后一个词来生成嵌入式表示:yt=f(x(t-1),xt,x(t+1))。
CNN 能够并行地计算,因此速度很快,但是由于是通过窗口来进行编码,所以更侧重于捕获局部信息,难以建模长距离的语义依赖。
Google《Attention is All You Need》提供了第三个方案:直接使用 Attention 机制编码整个文本。相比 RNN 要逐步递归才能获得全局信息(因此一般使用双向 RNN),而 CNN 实际只能获取局部信息,需要通过层叠来增大感受野,Attention 机制一步到位获取了全局信息:yt=f(xt,A,B)
其中A,B是另外的词语序列(矩阵),如果取A=B=X就称为 Self-Attention,即直接将xt与自身序列中的每个词语进行比较,最后算出yt。
Scaled Dot-product Attention
Scaled Dot-product Attention是最常见的attention实现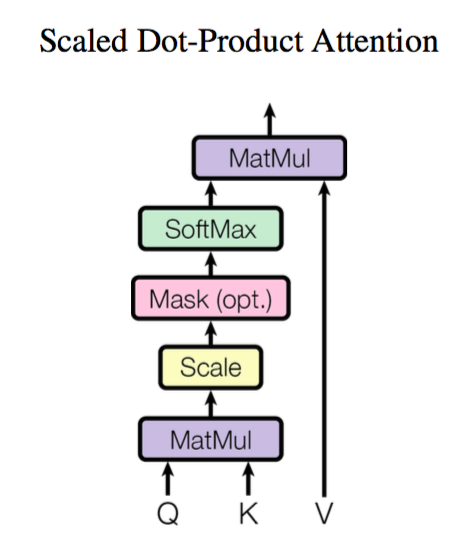
Scaled Dot-product Attention 共包含 2 个主要步骤:
- 计算注意力权重:使用某种相似度函数度量每一个 query 向量和所有 key 向量之间的关联程度。对于长度为 m 的 Query 序列和长度为 n 的 Key 序列,该步骤会生成一个尺寸为 m*n 的注意力分数矩阵。
特别地,Scaled Dot-product Attention 使用点积作为相似度函数,这样相似的 queries 和 keys 会具有较大的点积。
由于点积可以产生任意大的数字,这会破坏训练过程的稳定性。因此注意力分数还需要乘以一个缩放因子来标准化它们的方差,然后用一个 softmax 标准化。这样就得到了最终的注意力权重 w(ij),表示第 i 个 query 向量与第 j 个 key 向量之间的关联程度。 - 更新 token embeddings:将权重 w(ij) 与对应的 value 向量 v1,…,vn 相乘以获得第 i 个 query 向量更新后的语义表示 。